Preparing for Coding Interviews
My LeetCode Experience
Return all possible Valid String by removing minimum number of parentheses
Given a string s that contains parentheses and letters, remove the minimum number of invalid parentheses to make the input string valid.
Return all the possible results. You may return the answer in any order.
Example 1:
Input: s = "()())()"
Output: ["(())()","()()()"]Example 2:
Input: s = "(a)())()"
Output: ["(a())()","(a)()()"]Example 3:
Input: s = ")("
Output: [""]Solution:
The solution is to first identify the number of mismatched left and right brackets and then recurse in a DFS approach to generate the valid strings.
class Solution:
def __init__(self):
self.result = {}
def isValidString(self, s):
cnt = 0
for ch in s:
if ch == '(':
cnt += 1
elif ch == ')':
cnt = -1
if cnt != 0:
return False
return Truedef getUnmatchedParentheses(self, s):
result = {'(':0 , ')': 0}
for ch in s:
if ch == '(':
result[ch] += 1
elif ch == ')' and result['('] > 0:
result['('] -= 1
elif ch == ')' and result['('] == 0:
result[')'] += 1
return result
def removeInvalidParentheses(self, s):
def recurse(s, idx, left_count, right_count, left_rem, right_rem, expr):
if idx == len(s):
if left_rem == 0 and right_rem == 0:
ans = "".join(expr)
self.result[ans] = 1
else:
if (s[idx] == '(' and left_rem > 0):
recurse(s, idx+1, left_count, right_count, left_rem-1, right_rem, expr)
elif (s[idx] == ')' and right_rem > 0):
recurse(s, idx+1, left_count, right_count, left_rem, right_rem-1, expr)
expr.append(s[idx])
print(expr)
if s[idx] != '(' and s[idx] != ')':
recurse(s, idx+1, left_count, right_count, left_rem, right_rem, expr)
elif s[idx] == '(':
recurse(s, idx+1, left_count+1, right_count, left_rem, right_rem, expr)
elif s[idx] == ')' and left_count > right_count:
recurse(s, idx+1, left_count, right_count+1, left_rem, right_rem, expr)
expr.pop()
return None
tmp = self.getUnmatchedParentheses(s)
left, right = tmp['('], tmp[')']
recurse(s, 0, 0, 0, left, right, [])
return list(self.result.keys())
Time Complexity, O(2^N)
Space Complexity, O(N)
Convert Integer to English
Convert a non-negative integer num to its English words representation.
Example 1:
Input: num = 123
Output: "One Hundred Twenty Three"Example 2:
Input: num = 2345
Output: "Two Thousand Three Hundred Forty Five"Example 3:
Input: num = 3456789
Output: "Three Million Four Hundred Fifty Six Thousand Seven Hundred Eighty Nine"Example 4:
Input: num = 1234567891
Output: "One Billion Two Hundred Thirty Four Million Five Hundred Sixty Seven Thousand Eight Hundred Ninety One"Solution:
The numbers can usually be divided into chunks of 3 digits or Thousands, with the first 3 digits in the right representing 1000⁰.
It is better to ask some clarifying questions here:
- Are there any constraints on the number of value of the number processed? Can we set constraints like we can only do this up to a billion?
- Any other constraints we should be aware of?
- Assumption: The maximum value the integer is Octillion
- Step 1: Divided the Numbers into chunks of 3 digit numbers
- Step 2: Process this chunk to get the values
def numberToWords(num: int) -> str:
thousand_index = 0
word = ""
if num == 0:
return "Zero"
while num > 0:
segment = num % 1000
num = num // 1000
last_2_digits = (segment % 100)
last_digit = (segment % 10)
first_digit = segment // 100
middle_digit = last_2_digits // 10
subWord = ""
if last_2_digits > 9 and last_2_digits < 20:
subWord = {10:'Ten',
11:'Eleven',
12:'Twelve',
13:'Thirteen',
14:'Fourteen',
15:'Fifteen',
16:'Sixteen',
17:'Seventeen',
18:'Eighteen',
19:'Nineteen'}[last_2_digits]
if first_digit in {1:'One', 2:'Two',3:'Three',4:'Four',5:'Five',6:'Six',7:'Seven', 8:'Eight', 9: 'Nine'}.keys():
subWord = {1:'One',
2:'Two',
3:'Three',
4:'Four',
5:'Five',
6:'Six',
7:'Seven',
8:'Eight',
9: 'Nine'}[first_digit] + " Hundred " + subWord
else:
if first_digit > 0:
subWord = {1:'One',
2:'Two',
3:'Three',
4:'Four',
5:'Five',
6:'Six',
7:'Seven',
8:'Eight',
9: 'Nine'}[first_digit] + " Hundred "
if middle_digit > 1:
subWord += {2:'Twenty',
3:'Thirty',
4:'Forty',
5:'Fifty',
6:'Sixty',
7:'Seventy',
8:'Eighty',
9: 'Ninety'}[middle_digit]+" "
if last_digit > 0:
subWord += {1:'One',
2:'Two',
3:'Three',
4:'Four',
5:'Five',
6:'Six',
7:'Seven',
8:'Eight',
9: 'Nine'}[last_digit]
if thousand_index > 0:
if thousand_index == 1:
if subWord != "":
subWord += " Thousand "
elif thousand_index == 2:
if subWord != "":
subWord += " Million "
elif thousand_index == 3:
if subWord != "":
subWord += " Billion "
elif thousand_index == 4:
if subWord != "":
subWord += " Trillion "
elif thousand_index == 5:
if subWord != "":
subWord += " Quadrillion "
elif thousand_index == 6:
if subWord != "":
subWord += " Quintillion "
elif thousand_index == 7:
if subWord != "":
subWord += " Sextillion "
elif thousand_index == 8:
if subWord != "":
subWord += " Septillion "
elif thousand_index == 9:
if subWord != "":
subWord += " Octillion "
else:
return "Out of Bounds"
thousand_index += 1
word = subWord + word
subWord = ""
word = word.strip()
word = word.replace(" "," ")
return word- Time Complexity = O(N)
- Space Complexity = O(1)
Verifying an Alien Dictionary
In an alien language, surprisingly they also use english lowercase letters, but possibly in a different order. The order of the alphabet is some permutation of lowercase letters.
Given a sequence of words written in the alien language, and the order of the alphabet, return true if and only if the given words are sorted lexicographicaly in this alien language.
Example 1:
Input: words = ["hello","leetcode"], order = "hlabcdefgijkmnopqrstuvwxyz"
Output: true
Explanation: As 'h' comes before 'l' in this language, then the sequence is sorted.Example 2:
Input: words = ["word","world","row"], order = "worldabcefghijkmnpqstuvxyz"
Output: false
Explanation: As 'd' comes after 'l' in this language, then words[0] > words[1], hence the sequence is unsorted.Example 3:
Input: words = ["apple","app"], order = "abcdefghijklmnopqrstuvwxyz"
Output: false
Explanation: The first three characters "app" match, and the second string is shorter (in size.) According to lexicographical rules "apple" > "app", because 'l' > '∅', where '∅' is defined as the blank character which is less than any other character (More info).Solution:
The objective is to check if the words are in lexicographical order as provided. Therefore:
- We only need to check the adjacent words in a list
- If the left word has more letters than the right word, in the list, then return False
- Compare the indices of the first un-matching letters in the adjacent words in the order provided. If the index of the left un-matching is greater than that of the right un-matching character, return False
- If the above conditions are not met for any of the words in the list, return True
def isAlienSorted(words: List[str], order: str) -> bool:
'''
To make sure if the words are sorted lexicographically, it is enough if we compare only the adjacent words in the list
'''
for fw, sw in zip(words, words[1:]):
i = 0
while fw[i] == sw[i]:
if i < len(fw)-1 and i < len(sw) -1:
i += 1
else:
break
if fw[i] != sw[i] and order.find(fw[i]) > order.find(sw[i]):
return False
elif fw[i] == sw[i] and len(fw) > len(sw):
return False
return TrueTime Complexity: O(N), N-> number of letters in the list of words
Space Complexity: O(1)
Add Binary Strings
Given two binary strings a and b, return their sum as a binary string.
Example 1:
Input: a = "11", b = "1"
Output: "100"Example 2:
Input: a = "1010", b = "1011"
Output: "10101"Solution:
It is a simple problem but also can be tricky.
Approach 1:
- Convert the strings to Integer
- Add the binary values
- I’m not inclined to this approach because, the length of the string would be limited by the size of the Integer/LongInt variables and may become slow for large strings
- Time Complexity: O(N+M)
- Space Complexity: O(max(M, N)
Approach 2:
- Convert the strings to Integer
- Compute the Sum as the XOR of the two Integers. (Sum = x^y)
- Compute the Carry part using AND operator. (carry = (x&y)<<1)
- The pseudo code for this approach in Python would something like this:
def addBinaryStrings(x: str, y: str) -> str:
x, y = int(x,2), int(y, 2)
x, y = x ^ y, (x & y) << 1
while y:
x, y = x ^ y, (x & y) << 1
return bin(x)[2:]- Time Complexity: O(N+M)
- Space Complexity: O(max(N,M))
- This is an improvement on the Approach 1, operationally. However, it leaves much to be desired.
Approach 3:
By far this my favourite approach. This is a straight forward string manipulation. Hence, it has the following benefits:
- The length of the string is only limited by the machine memory, so you can proceed to have strings (together) to be GBs!
- It is has a better Time Complexity.
One problem with this approach would be that debugging, if something goes wrong will be a pain.
def addBinary(a: str, b: str) -> str:
carry = "0" # initiate carry
answer = "" # initiate answer
if len(a) > len(b):
for i in range(len(a)-len(b)):
b = "0" + b
if len(a) < len(b):
for i in range(len(b)-len(a)):
a = "0" + a
for i in range(len(a)-1,-1, -1):
partial_answer = ""
if a[i] == "0" and b[i] == "0":
if carry == "0":
partial_answer = "0"
carry = "0"
elif carry == "1":
partial_answer = "1"
carry = "0"
if a[i] == "0" and b[i] == "1":
if carry == "0":
partial_answer = "1"
carry = "0"
elif carry == "1":
partial_answer = "0"
carry = "1"
if a[i] == "1" and b[i] == "0":
if carry == "0":
partial_answer = "1"
carry = "0"
elif carry == "1":
partial_answer = "0"
carry = "1"
if a[i] == "1" and b[i] == "1":
if carry == "0":
partial_answer = "0"
carry = "1"
elif carry == "1":
partial_answer = "1"
carry = "1"
answer = partial_answer + answer
if carry is not "0":
answer = carry + answer
return answerTime Complexity: O(max(M, N))
Space Complexity: O(max(M, N))
Note: Please inquire your interviewer for clarification on the limitations before selecting the approach
Remove Minimum Parentheses to Make it Valid
Given a string s of '(' , ')' and lowercase English characters.
Your task is to remove the minimum number of parentheses ( '(' or ')', in any positions ) so that the resulting parentheses string is valid and return any valid string.
Formally, a parentheses string is valid if and only if:
- It is the empty string, contains only lowercase characters, or
- It can be written as
AB(Aconcatenated withB), whereAandBare valid strings, or - It can be written as
(A), whereAis a valid string.
Example 1:
Input: s = "lee(t(c)o)de)"
Output: "lee(t(c)o)de"
Explanation: "lee(t(co)de)" , "lee(t(c)ode)" would also be accepted.Example 2:
Input: s = "a)b(c)d"
Output: "ab(c)d"Example 3:
Input: s = "))(("
Output: ""
Explanation: An empty string is also valid.Example 4:
Input: s = "(a(b(c)d)"
Output: "a(b(c)d)"Constraints:
s[i]is one of'(',')'and lowercase English letters
Solution:
Approach 1:
This is very similar to the previous code example, here.
The solution follows the same logic.
- if the length of the string is 0, return an empty string
- Strip all ‘)’ at the start of the string
- Strip all ‘(‘ at the end of the string
- if the string is empty return an empty string
- Remove a character in the outer loop
- The inner loop, loops around the substring created by removing the character in the outer loop
- count the number of left brackets and right brackets.
- Don’t include the right brackets without corresponding left brackets
- Check if the constructed solution is valid, if so return the solution
The code is as follows:
def minRemoveToMakeValid(s: str) -> str:
# return if the string is empty to start with
if len(s) <= 0:
return ""
# Strip ')' at the start of the string
s = s.lstrip(')')
# Strip '(' at the end of the string
s = s.rstrip('(')
# Return if string is empty
if len(s) <= 0:
return ""
# Outer Loop, Remove 1 character in the string at a time
for i in range(-1,len(s)):
# Creating the Substring
if i < 0:
subStr = s
else:
subStr = s[:i]+s[i+1:]
#Initiate variables to track brackets and solutions
left_count, right_count, solution = 0, 0, ""
for j in range(len(subStr)):
if subStr[j] == '(':
left_count +=1
solution += subStr[j]
elif subStr[j] == ')':
if right_count <= left_count:
right_count += 1
solution += subStr[j]
else:
solution += subStr[j]
if left_count == right_count:
return solution
return NoneTime Complexity: O(N²)
Space Complexity: O(N)
While this can be a one stop solution, your interviewer may not like it. However, if you may ask if he or she would prefer a solution that is much more general in listing out all the possible solutions.
Approach 2:
There exists a much easier solution to this, using stacks.
For the string to be valid the right and left brackets should match. Any excess brackets needs to be removed.
- If the input string is empty or None, return an empty string (Trivial Case)
- Initialize Stack
- Initialize Left Bracket Tracker (LBT)
- Navigate the string left to right
- On encountering a ‘(‘, add the index to stack, increment the LBT
- On encountering ‘)’, if LBT > 0, decrement LBT and pop the last entered value in the stack
- On encountering ‘)’, if LBT ≤ 0, add index to the stack
- Construct the solution by excluding the characters at the index of the stack
def minRemoveToMakeValid(s: str) -> str:
# Return on encountering an empty string
if len(s) == 0 or s == "" or s is None: return ""
indices_to_remove = []
lf_bracket_pushed = 0
for i in range(len(s)):
if s[i] == '(':
indices_to_remove.append(i)
lf_bracket_pushed += 1
elif s[i] == ')' and lf_bracket_pushed > 0:
indices_to_remove.pop()
lf_bracket_pushed -= 1
elif s[i] == ')' and lf_bracket_pushed <= 0:
indices_to_remove.append(i)
solution = ""
for i in range(len(s)):
if i not in indices_to_remove:
solution += s[i]
return solutionTime Complexity: O(N)
Space Complexity: O(N)
Find the Leftmost Column with at Least a One
A row-sorted binary matrix means that all elements are 0 or 1 and each row of the matrix is sorted in non-decreasing order.
Given a row-sorted binary matrix binaryMatrix, return the index (0-indexed) of the leftmost column with a 1 in it. If such an index does not exist, return -1.
You can’t access the Binary Matrix directly. You may only access the matrix using a BinaryMatrix interface:
BinaryMatrix.get(row, col)returns the element of the matrix at index(row, col)(0-indexed).BinaryMatrix.dimensions()returns the dimensions of the matrix as a list of 2 elements[rows, cols], which means the matrix isrows x cols.
Submissions making more than 1000 calls to BinaryMatrix.get will be judged Wrong Answer. Also, any solutions that attempt to circumvent the judge will result in disqualification.
For custom testing purposes, the input will be the entire binary matrix mat. You will not have access to the binary matrix directly.
Example 1:

Input: mat = [[0,0],[1,1]]
Output: 0Example 2:

Input: mat = [[0,0],[0,1]]
Output: 1Example 3:

Input: mat = [[0,0],[0,0]]
Output: -1Example 4:

Input: mat = [[0,0,0,1],[0,0,1,1],[0,1,1,1]]
Output: 1Constraints:
rows == mat.lengthcols == mat[i].length1 <= rows, cols <= 100mat[i][j]is either0or1.mat[i]is sorted in non-decreasing order.
Solution:
Approach 1:
Search the matrix one cell at a time. This is most rudimentary approach. This approach has a Time Complexity of O(MN), where ‘M’ is the number of rows and ’N’ is the number of columns in the binary matrix.
Approach 2:
The above approach can be improved a bit better by using binary search in each row. This will yield a Time Complexity of O(M log N), where ‘M’ is the number of rows and ’N’ is the number of columns in the binary matrix.
Approach 3:
In this approach, you can traverse column wise.
def leftMostColumnWithOne(binaryMatrix):
"""
:type binaryMatrix: BinaryMatrix
:rtype: int
"""
row, col = binaryMatrix.dimensions()
num_api_calls = 0
for j in range(col):
for i in range(row):
if binaryMatrix.get(i,j) == 1:
num_api_calls += 1
return j
return -1This is not a great approach, as if there are no 1s in the matrix, we would traverse all the cells in the matrix leading to a worst Time Complexity of O(MN), where ‘M’ is the number of rows and ’N’ is the number of columns in the binary matrix.
Approach 4:
Since the matrix is sorted, if you encounter a 1 in a row, all cells to the right would have only 1s.
Also, the first column index can only be in to the right of this 1.
So, the approach is as follows:
- Start at the top right corner (0, N-1)
- if the value of a cell is 1, move right
- if the value of the cell is 0, move down
class Solution(object):
def leftMostColumnWithOne(binaryMatrix):
"""
:type binaryMatrix: BinaryMatrix
:rtype: int
"""
row, col = binaryMatrix.dimensions()
col_idx, min_idx = col-1, 999
api_count = 0
for i in range(row):
for j in range(col_idx, -1, -1):
val = binaryMatrix.get(i, j)
api_count += 1
if val == 1:
min_idx = min(min_idx, j)
if val == 0:
col_idx = j
break
if min_idx >= col: min_idx = -1
print("Total Number of API calls:", api_count)
return min_idxK Closest Points to Origin
Given an array of points where points[i] = [xi, yi] represents a point on the X-Y plane and an integer k, return the k closest points to the origin (0, 0).
The distance between two points on the X-Y plane is the Euclidean distance (i.e., √(x1 - x2)2 + (y1 - y2)2).
You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in).
Example 1:

Input: points = [[1,3],[-2,2]], k = 1
Output: [[-2,2]]
Explanation:
The distance between (1, 3) and the origin is sqrt(10).
The distance between (-2, 2) and the origin is sqrt(8).
Since sqrt(8) < sqrt(10), (-2, 2) is closer to the origin.
We only want the closest k = 1 points from the origin, so the answer is just [[-2,2]].Example 2:
Input: points = [[3,3],[5,-1],[-2,4]], k = 2
Output: [[3,3],[-2,4]]
Explanation: The answer [[-2,4],[3,3]] would also be accepted.Constraints:
1 <= k <= points.length <= 10^4-10^4 < xi, yi < 10^4
Solution:
Approach 1:
The easiest and the straight forward approach is to sort all the distances return the first ‘k’ points
def kClosest(points, K):
points.sort(key = lambda P: P[0]**2 + P[1]**2)
return points[:K]Time Complexity: O(N log N)
Space Complexity: O(N)
Approach 2:
There is no need to sort all distances. Similarly, it is enough to only retain the ‘K’ smallest distances.
def kClosest(points: List[List[int]], k: int) -> List[List[int]]:
look_up = {}
for i in range(len(points)):
d2 = points[i][0]**2 + points[i][1]**2
if len(look_up.keys()) < k:
look_up[d2] = points[i]
else:
d2_list = sorted(list(look_up.keys()))
if (d2_list[-1]-d2) > 0:
look_up.pop(d2_list[-1])
look_up[d2] = points[i]
return look_up.values()For each point in the list, ‘k’ values are sorted.
Time Complexity: O (N log k); k<<N
Space Complexity: O(k); k<<N
Approach 3:
The above approach can be improved further.
def kClosest(points: List[List[int]], k: int) -> List[List[int]]:
left_bucket, right_bucket = points[:k], points[k:]
left_bucket.sort(key = lambda P: P[0]**2 + P[1]**2)
for point in right_bucket:
if (point[0]**2+point[1]**2) < (left_bucket[-1][0]**2 + left_bucket[-1][1]**2):
left_bucket[-1] = point
left_bucket.sort(key = lambda P: P[0]**2 + P[1]**2)
return left_bucketTime Complexity: O(log k + (N-k) log k) = O((N-k+1) log k)
Space Complexity: O(N)
Valid Palindrome
Given a non-empty string s, you may delete at most one character. Judge whether you can make it a palindrome.
Example 1:
Input: "aba"
Output: TrueExample 2:
Input: "abca"
Output: True
Explanation: You could delete the character 'c'.Solution:
Approach 1:
Move from the start of the string and end of the string. If there is a mismatch of characters, then check if deleting either of the character can make the reminder of the string a palindrome.
def validPalindrome(s: str) -> bool:
left_index, right_index = 0, len(s)-1
while left_index < right_index:
if s[left_index] != s[right_index]:
a = s[:left_index]+s[left_index+1:]
b = s[:right_index]+s[right_index+1:]
return a == a[::-1] or b == b[::-1]
left_index += 1
right_index -= 1
return TrueTime Complexity: O(N)
Space Complexity: O(1)
Dot Product of two SparseVectors
Given two sparse vectors, compute their dot product.
Implement class SparseVector:
SparseVector(nums)Initializes the object with the vectornumsdotProduct(vec)Compute the dot product between the instance of SparseVector andvec
A sparse vector is a vector that has mostly zero values, you should store the sparse vector efficiently and compute the dot product between two SparseVector.
Follow up: What if only one of the vectors is sparse?
Example 1:
Input: nums1 = [1,0,0,2,3], nums2 = [0,3,0,4,0]
Output: 8
Explanation: v1 = SparseVector(nums1) , v2 = SparseVector(nums2)
v1.dotProduct(v2) = 1*0 + 0*3 + 0*0 + 2*4 + 3*0 = 8Example 2:
Input: nums1 = [0,1,0,0,0], nums2 = [0,0,0,0,2]
Output: 0
Explanation: v1 = SparseVector(nums1) , v2 = SparseVector(nums2)
v1.dotProduct(v2) = 0*0 + 1*0 + 0*0 + 0*0 + 0*2 = 0Example 3:
Input: nums1 = [0,1,0,0,2,0,0], nums2 = [1,0,0,0,3,0,4]
Output: 6Constraints:
n == nums1.length == nums2.length1 <= n <= 10^50 <= nums1[i], nums2[i] <= 100
Solution:
Approach 1:
Check if the vectors are not of the same length, exit due to missing dimensions
Convert the sparse vector by storing in the dictionary
Check for common indices and compute the dot product from them
class SparseVector:
def __init__(self, nums: List[int]):
self.sparse_num = {}
self.length_nums = len(nums)
for i, n in enumerate(nums):
if n != 0:
self.sparse_num[i] = n# Return the dotProduct of two sparse vectors
def dotProduct(self, vec: 'SparseVector') -> int:
dotproduct = 0
if self.length_nums != vec.length_nums:
return None
else:
for k in self.sparse_num.keys():
if k in vec.sparse_num.keys():
dotproduct += self.sparse_num[k] * vec.sparse_num[k]
return dotproduct
Time Complexity: O(N), for creating the sparse vector. Let L¹, L² be the two sparse vectors. Then the time complexity for computing dot product is O(L¹), where L¹ < L².
Space Complexity: O(L), for creating the hash map. O(1) for creating dot product
Product of Array Except Self
Given an integer array nums, return an array answer such that answer[i] is equal to the product of all the elements of nums except nums[i].
The product of any prefix or suffix of nums is guaranteed to fit in a 32-bit integer.
Example 1:
Input: nums = [1,2,3,4]
Output: [24,12,8,6]Example 2:
Input: nums = [-1,1,0,-3,3]
Output: [0,0,9,0,0]Constraints:
2 <= nums.length <= 105-30 <= nums[i] <= 30- The product of any prefix or suffix of
numsis guaranteed to fit in a 32-bit integer.
Follow up:
- Could you solve it in
O(n)time complexity and without using division? - Could you solve it with
O(1)constant space complexity? (The output array does not count as extra space for space complexity analysis.)
Solution:
The approach will be much clear if we rephrase the problem as “For every element in a list find the product of the elements to its left and right”
Let X be a list of length N (indices are shown in the image below)

Now, lets pick an element at index ‘i’ in the array.
Then,
Product of all elements excluding the element at ‘i’ can be given by product of all elements to its left and to its right:

The interesting thing about this approach is that if one keeps tracks of the products from left to right (or vice versa), to compute the product of elements in the left, they have to only obtain the last left product computed and multiply it with the number in the left. Similarly, one can compute the right products as well.
We can compute separate arrays for tracking the left and right products. However, that would be a bit cumbersome and is not needed. So, we’ll only keep track of the elements that we need.
- Initiate an answer array 1’s (1 multiplied by any number is the same number)
- First we’ll calculate the left products and update it with right products.
- Set answer[0] = 1 (as there are no elements towards the left of the leftmost element)
- Traverse from index 1 to N. During each iteration obtain the product of the i-1 in the answer array and number array and store it at the index ‘i’ in the answer array.
- Now traverse from N to 0.
- Since there are no elements to the right of the last element, we start with 1. That is the last element in the answer array wouldn’t be changed
- The N-1 element in the answer array, would be multiplied by the N-th element of the number array and etc.,
There are two passes, one for initiating the values with the left products and update pass for the final answer array. Therefore,
Time Complexity: O(N+N) ~ O(N)
Space Complexity: O(N) for the answer array; O(1) for storing intermediate results
def productExceptSelf(nums: List[int]) -> List[int]:
output = [1] * len(nums)
for i in range(1,len(nums)):
output[i] = output[i-1] * nums[i-1]
R = 1
for i in reversed(range(len(nums))):
output[i] = output[i] * R
R *= nums[i]
return outputSubarray Sum Equals K
Given an array of integers nums and an integer k, return the total number of continuous subarrays whose sum equals to k.
Example 1:
Input: nums = [1,1,1], k = 2
Output: 2Example 2:
Input: nums = [1,2,3], k = 3
Output: 2Solution:
There are many approaches to this problem. However, most of the algorithms have a time complexity O(N²). The most optimal solution would the one with a Time Complexity of O(N) and a space complexity O(N). This the solution presented here:
def subarraySum(nums: List[int], k: int) -> int:
total_number_of_subarrays = 0
cumulative_sum = 0
hash_map = {0:1}
for itm in nums:
cumulative_sum += itm
if (cumulative_sum-k) in hash_map.keys():
total_number_of_subarrays += hash_map[cumulative_sum-k]
if cumulative_sum in hash_map.keys():
hash_map[cumulative_sum] += 1
else:
hash_map[cumulative_sum] = 1
return total_number_of_subarraysWe are storing the partial sums. Hence, the Space Complexity O(N).
Add Strings of Numbers
Given two non-negative integers, num1 and num2 represented as string, return the sum of num1 and num2 as a string.
Example 1:
Input: num1 = "11", num2 = "123"
Output: "134"Example 2:
Input: num1 = "456", num2 = "77"
Output: "533"Example 3:
Input: num1 = "0", num2 = "0"
Output: "0"Constraints:
1 <= num1.length, num2.length <= 104num1andnum2consist of only digits.num1andnum2don't have any leading zeros except for the zero itself.
Solution:
def addStrings(num1: str, num2: str) -> str:
carry, value, final_sum = 0, 0, ""
idx1, idx2 = len(num1)-1, len(num2)-1
while idx1 >= 0 or idx2 >= 0:
x1 = ord(num1[idx1]) - ord("0") if idx1 >= 0 else 0
x2 = ord(num2[idx2]) - ord("0") if idx2 >= 0 else 0
value = (x1 + x2 + carry) % 10
carry = (x1 + x2 + carry) // 10
final_sum = str(value) + final_sum
idx1, idx2 = idx1-1, idx2-1
if carry > 0:
final_sum = str(carry) + final_sum
return final_sumTime Complexity: O(max(N1, N2))
Space Complexity: O(max(N1, N2)+1)
Trie Structure
This is one of the favourite questions for the interviewers. There are many variations to play with. Here we are going to:
- Design and Create a data structure that supports adding new words and finding if a string matches any previously added string.
- Create a code to add new words
- Search the dictionary if a given word exists
- Search the dictionary if a given prefix exists
- Search the dictionary if a given pattern exists: “.ad”, “b..”, etc. In these case, the expected words are 3 characters are long. In the first example the first character can be anything, in the second example the last two characters can be anything
Solution:
class WordDictionary:
def __init__(self):
self.trie = {} def add_word(self, word:str) -> None:
node = self.trie
for ch in word:
if ch not in node:
node[ch] = {}
node = node[ch]
node['$'] = True def search_prefix(self, prefix: str) -> bool:
node = self.trie
for ch in prefix:
if ch not in node: return False
node = node[ch]
return True def search_word(self, word:str) -> bool:
node = self.trie
for ch in word:
if ch not in node: return False
node = node[ch]
return node['$'] def search_pattern(self, word: str) -> book:
def search_recursive(node, word):
for i in range(len(word)):
if word[i] not in node:
if word[i] == '.':
for x in node:
if x != '$' and search_recursive(node[x], word[i+1:]):return True
return False
else:
node = node[word[i]]
return '$' in node
return search_recursive(self.trie, word)
Time Complexity:
- Add Word — O(M); M ->Length of the Word
- Search Prefix — O(M); M-> Length of prefix
- Search Word — O(M); M -> Length of Word
- Search Pattern -> For words in the dictionary it is O(M), where M is the length of the words. However, in the worst case scenario where the entire pattern is dots, it may take O(N. 26^M); where N is the number of entries/keys and ‘M’ is the length of the given key.
Space Complexity:
- For Adding word, search prefix, Search Word, or search pattern it is O(1) for well-defined words
- However, it is O(M) for undefined words
Maximum Path Sum
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
Solution:
The solution is straight forward. Have a recursive function for a depth first search and accumulate sums.
def maxPathSum(root: TreeNode) -> int:
def max_gain(node):
nonlocal max_sum
if not node: return 0
left_gain = max(max_gain(node.left), 0)
right_gain = max(max_gain(node.right), 0)
new_sum = node.val +left_gain+right_gain
max_sum = max(max_sum, new_sum)
return node.val + max(left_gain, right_gain)
max_sum = float(-inf)
max_gain(root)
return max_sumTime Complexity: O(N) where N is the number of Nodes.
Space Complexity: O(H), where H is the height of the tree, due to the recursive stack.
Merge Intervals
Given an array of intervals where intervals[i] = [starti, endi], merge all overlapping intervals, and return an array of the non-overlapping intervals that cover all the intervals in the input.
Example 1:
Input: intervals = [[1,3],[2,6],[8,10],[15,18]]
Output: [[1,6],[8,10],[15,18]]
Explanation: Since intervals [1,3] and [2,6] overlaps, merge them into [1,6].Example 2:
Input: intervals = [[1,4],[4,5]]
Output: [[1,5]]
Explanation: Intervals [1,4] and [4,5] are considered overlapping.Solution:
The approach goes like this:
- If the start_i > end_(i-1), then add the interval_(i-1) to the solution.
- If not, see if you can merge them.
def merge(intervals: List[List[int]]) -> List[List[int]]:
intervals.sort(key=lambda x: x[0])
solution = []
prev = intervals[0]
for curr in intervals[1:]:
lower_limit = min([prev[0], curr[0]])
upper_limit = max([prev[1], curr[1]])
if curr[0] > prev[1]:
solution.append(prev)
prev = curr
else:
prev[0], prev[1] = [lower_limit, upper_limit]
solution.append(prev)
return solutionTime Complexity:
- Initial Sort = O(log N)
- Traversal Comparing adjacent Intervals: O(N-1)
- Total = O(log N) + O(N-1)
Space Complexity:
- For sorting: O(log N)
- For solutions: O(N)
Valid Palindrome by Deletion
Given a string s, return true if the s can be palindrome after deleting at most one character from it.
Example 1:
Input: s = "aba"
Output: trueExample 2:
Input: s = "abca"
Output: true
Explanation: You could delete the character 'c'.Example 3:
Input: s = "abc"
Output: falseSolution:
Traverse the string from left to right
Remove each character in the string and check if the remaining characters form a palindrome
def validPalindrome(s: str) -> bool:
for i in range(len(s)):
sub_string = s[:i]+s[i+1:]
if sub_string == sub_string[::-1]:
return True
return FalseTime Complexity: O(N)
Space Complexity: O(1)
Buildings With an Ocean View
There are n buildings in a line. You are given an integer array heights of size n that represents the heights of the buildings in the line.
The ocean is to the right of the buildings. A building has an ocean view if the building can see the ocean without obstructions. Formally, a building has an ocean view if all the buildings to its right have a smaller height.
Return a list of indices (0-indexed) of buildings that have an ocean view, sorted in increasing order.
Example 1:
Input: heights = [4,2,3,1]
Output: [0,2,3]
Explanation: Building 1 (0-indexed) does not have an ocean view because building 2 is taller.Example 2:
Input: heights = [4,3,2,1]
Output: [0,1,2,3]
Explanation: All the buildings have an ocean view.Example 3:
Input: heights = [1,3,2,4]
Output: [3]
Explanation: Only building 3 has an ocean view.Example 4:
Input: heights = [2,2,2,2]
Output: [3]
Explanation: Buildings cannot see the ocean if there are buildings of the same height to its right.Solution:
The solution to this problem is quite simple, if you rephrase the problem as follows:
“List the indices in reversed order of integers in a list if a given integer is greater than the greater integer to its right.”
def findBuildings(heights: List[int]) -> List[int]:
indices = [len(heights)-1]
prev_tallest_to_right = heights[-1]
for i in range(len(heights)-2, -1, -1):
if heights[i] > prev_tallest_to_right:
indices.append(i)
prev_tallest_to_right = heights[i]
indices = reversed(indices)
return indicesTime Complexity:
- Traversal of heights from right to left: O(N-1)
- Reversal of indices: O(N)
- Total Time Complexity: O(2N-1) ~ O(N)
Space Complexity:
- For storing the results: O(K); where ‘K’ is the number of buildings with ocean view
- Worst Case: O(N); when all building to the right are smaller
Minimum Moves to Move a Box to Their Target Location
Storekeeper is a game in which the player pushes boxes around in a warehouse trying to get them to target locations.
The game is represented by a grid of size m x n, where each element is a wall, floor, or a box.
Your task is move the box 'B' to the target position 'T' under the following rules:
- Player is represented by character
'S'and can move up, down, left, right in thegridif it is a floor (empy cell). - Floor is represented by character
'.'that means free cell to walk. - Wall is represented by character
'#'that means obstacle (impossible to walk there). - There is only one box
'B'and one target cell'T'in thegrid. - The box can be moved to an adjacent free cell by standing next to the box and then moving in the direction of the box. This is a push.
- The player cannot walk through the box.
Return the minimum number of pushes to move the box to the target. If there is no way to reach the target, return -1.
Input: grid = [["#","#","#","#","#","#"],
["#","T","#","#","#","#"],
["#",".",".","B",".","#"],
["#",".","#","#",".","#"],
["#",".",".",".","S","#"],
["#","#","#","#","#","#"]]
Output: 3
Explanation: We return only the number of times the box is pushed.Example 2:
Input: grid = [["#","#","#","#","#","#"],
["#","T","#","#","#","#"],
["#",".",".","B",".","#"],
["#","#","#","#",".","#"],
["#",".",".",".","S","#"],
["#","#","#","#","#","#"]]
Output: -1Example 3:
Input: grid = [["#","#","#","#","#","#"],
["#","T",".",".","#","#"],
["#",".","#","B",".","#"],
["#",".",".",".",".","#"],
["#",".",".",".","S","#"],
["#","#","#","#","#","#"]]
Output: 5
Explanation: push the box down, left, left, up and up.Example 4:
Input: grid = [["#","#","#","#","#","#","#"],
["#","S","#",".","B","T","#"],
["#","#","#","#","#","#","#"]]
Output: -1Solution:
IMHO, this problem is tricky. The first instance of the problem would make one think of the A* or Djisktra algorithm for finding the least number of pushes, which is in other words the shortest path, until one realizes that there are two entities the box and the player.
The player has to be in the right position for the box to be pushed. So, think the problem as Target and a dynamic state of player and box together.
Since we need only the minimum number of pushes, maintain two stacks. One that collects all the states that results in a push and another that records state changes of the player and box.
While coding the algorithm consider the following cases:
- There is a clear path between the player and the box, and, box and the target. Ex. they are in a straight line.
- After some pushes the player may need to back track and find another way to proceed
- The player may not be able to reach the box, or the box may not be reachable
The following code should explain it better:
def minPushBox(grid: List[List[str]]) -> int:
def getCoordinates():
player, box, target = None, None, None
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == 'S':
player = (i,j)
elif grid[i][j] == 'B':
box = (i,j)
elif grid[i][j] == 'T':
target = (i,j)
return player, box, target
def getNextState(currentPlayerState, currentBoxState):
right, left, down, up = (0,1), (0,-1), (1,0), (-1,0)
moves = [up, down, left, right]
for move in moves:
nextPlayerState = (currentPlayerState[0]+move[0], currentPlayerState[1]+move[1])
if nextPlayerState[0] < 0 or nextPlayerState[0] >= len(grid):
continue
if nextPlayerState[1] < 0 or nextPlayerState[1] >= len(grid[0]):
continue
if grid[nextPlayerState[0]][nextPlayerState[1]] == '#':
continue
if currentBoxState != nextPlayerState:
yield (nextPlayerState, currentBoxState, False)
continue
nextBoxState = (currentBoxState[0]+move[0], currentBoxState[1]+move[1])
if nextBoxState[0] < 0 or nextBoxState[0] >= len(grid):
continue
if nextBoxState[1] < 0 or nextBoxState[1] >= len(grid[0]):
continue
if grid[nextBoxState[0]][nextBoxState[1]] == '#':
continue
yield (nextPlayerState, nextBoxState, True)player, box, target = getCoordinates()
outer_stack = collections.deque([(player, box, 0)])
visited = set([(player, box)])
while len(outer_stack) > 0:
player, box, numPushes = outer_stack.popleft()
if box == target:
return numPushes
inner_stack = collections.deque([(player, box)])
while len(inner_stack) > 0:
current_player_state, current_box_state = inner_stack.popleft()
for next_player_state, next_box_state, can_push in getNextState(current_player_state,current_box_state):
if (next_player_state, next_box_state) not in visited:
if can_push:
outer_stack.append((next_player_state, next_box_state, numPushes+1))
else:
inner_stack.append((next_player_state, next_box_state))
visited.add((next_player_state, next_box_state))
return -1
Making a Large Island
You are given an n x n binary matrix grid. You are allowed to change at most one 0 to be 1.
Return the size of the largest island in grid after applying this operation.
An island is a 4-directionally connected group of 1s.
Example 1:
Input: grid = [[1,0],[0,1]]
Output: 3
Explanation: Change one 0 to 1 and connect two 1s, then we get an island with area = 3.Example 2:
Input: grid = [[1,1],[1,0]]
Output: 4
Explanation: Change the 0 to 1 and make the island bigger, only one island with area = 4.Example 3:
Input: grid = [[1,1],[1,1]]
Output: 4
Explanation: Can't change any 0 to 1, only one island with area = 4.Solution:
The naive approach to this problem is to identify the location of the zeros and find the island size by changing one 0 at a time. However, this is not an optimal solution.
The optimal solution may be something like an image segmentation algorithm, where all connected pixels of same colour are the assigned the same label. Here we do the same. We make a depth-first-search to identify all connected 1’s and assign them to a group, as a first step. In the next step, we visit the 0, find their neighbours and if any indices have been assigned to them earlier. If so, the area of the group is compared with other areas to find the biggest island.
In simple terms, find the 1’s segments and their areas. Followed, by finding the 0’s segments and their neighbours.
def largestIsland(self, grid: List[List[int]]) -> int:
N = len(grid)
def neighbours(r,c):
up, down, right, left = (-1,0),(1,0),(0,1), (0,-1)
for x, y in [up, down, right, left]:
nr, nc = r+x, c+y
if 0 <= nr < N and 0 <= nc < N:
yield nr, nc
def dfs(r, c, index):
ans = 1
grid[r][c] = index
for nr, nc in neighbours(r,c):
if grid[nr][nc] == 1:
ans += dfs(nr, nc, index)
return ans# Segment 1’s into different groups and get their size area = {}
index = 2
for i in range(N):
for j in range(N):
if grid[i][j] == 1:
area[index] = dfs(i,j, index)
index += 1
ans = max(area.values or [0])# Gets 0s and fetch its neighbours to get areas for i in range(N):
for j in range(N)
if grid[i][j] == 0:
seen = {grid[nr][nc] for nr, nc in neighbours(i,j) if grid[nr][nc] > 1}
ans = max(ans, 1+sum(area[i] for i in seen)
return ans
Convert Binary Search Tree to Sorted Doubly Linked List
Convert a Binary Search Tree to a sorted Circular Doubly-Linked List in place.
You can think of the left and right pointers as synonymous to the predecessor and successor pointers in a doubly-linked list. For a circular doubly linked list, the predecessor of the first element is the last element, and the successor of the last element is the first element.
We want to do the transformation in place. After the transformation, the left pointer of the tree node should point to its predecessor, and the right pointer should point to its successor. You should return the pointer to the smallest element of the linked list.
Example 1:

Input: root = [4,2,5,1,3]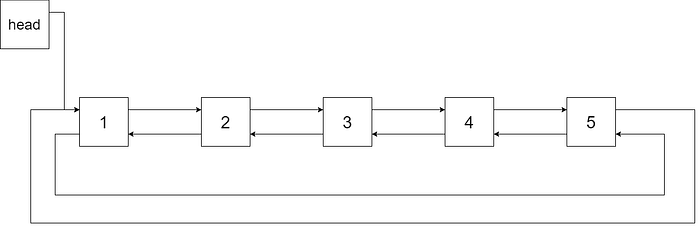
Output: [1,2,3,4,5]Explanation: The figure below shows the transformed BST. The solid line indicates the successor relationship, while the dashed line means the predecessor relationship.
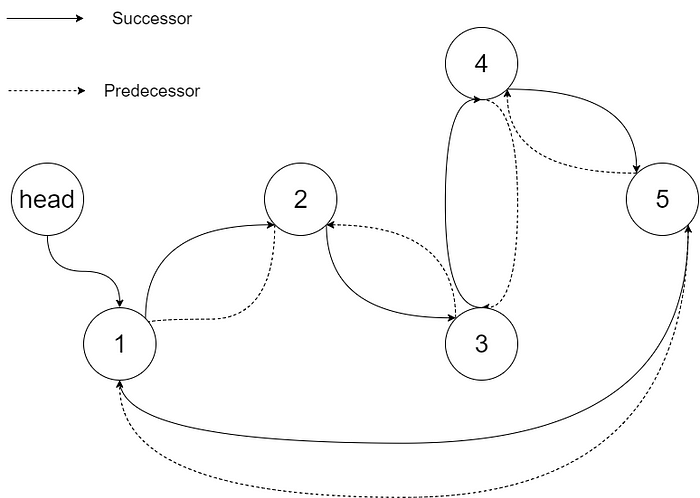
Example 2:
Input: root = [2,1,3]
Output: [1,2,3]Example 3:
Input: root = []
Output: []
Explanation: Input is an empty tree. Output is also an empty Linked List.Example 4:
Input: root = [1]
Output: [1]Solution:
This is a simple in-order tree traversal. A modification to this is that we have to maintain two pointers, first and last. The first pointer will point to the very first node, while the last pointer keeps moving until the last node is reached, when these two nodes will be linked.
def treeToDoublyList(self, root: 'Node') -> 'Node':
first, last = None, None
def traverse(node):
nonlocal first, last
if node:
traverse(node.left)
if last:
last.left = node
node.right = last
else:
first = node
last = node
traverse(node.right)
if root:
traverse( root )
first.right = last
last.left = right
return first
else:
return NoneRange Sum of a Binary Search Tree
Given the root node of a binary search tree and two integers low and high, return the sum of values of all nodes with a value in the inclusive range [low, high].
Example 1:

Input: root = [10,5,15,3,7,null,18], low = 7, high = 15
Output: 32
Explanation: Nodes 7, 10, and 15 are in the range [7, 15]. 7 + 10 + 15 = 32.Example 2:

Input: root = [10,5,15,3,7,13,18,1,null,6], low = 6, high = 10
Output: 23
Explanation: Nodes 6, 7, and 10 are in the range [6, 10]. 6 + 7 + 10 = 23.Solution:
This is a simple pre-order traversal of the search tree. However, since there are ranges, we only traverse the left branch if the current node value is greater than the lower range. Similarly, we will traverse the right branch if current node value is less the upper range value. We only add the node values that fall within the range
ef rangeSumBST(self, root: TreeNode, low: int, high: int) -> int:
range_sum = 0
def dfs(node):
nonlocal range_sum
if node:
if low <= node.val <= high: range_sum += node.val
if low < node.val: dfs(node.left)
if node.val < high: dfs(node.right)
dfs(root)
return range_sumLowest Common Ancestor of a Binary Tree
Given two nodes of a binary tree p and q, return their lowest common ancestor (LCA).
Each node will have a reference to its parent node. The definition for Node is below:
class Node {
public int val;
public Node left;
public Node right;
public Node parent;
}According to the definition of LCA on Wikipedia: “The lowest common ancestor of two nodes p and q in a tree T is the lowest node that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Example 1:

Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
Output: 3
Explanation: The LCA of nodes 5 and 1 is 3.Example 2:

Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
Output: 5
Explanation: The LCA of nodes 5 and 4 is 5 since a node can be a descendant of itself according to the LCA definition.Example 3:
Input: root = [1,2], p = 1, q = 2
Output: 1Solution:
The approach is as follows:
- Traverse the node from ‘p’, all the way to root and the store the ancestors during the process
- Traverse the node from ‘q’, all the way to root and the store the ancestors during the process
- Go through the list of the ancestors and find the first node of divergence.
def lowestCommonAncestor( p, q):
def dfs_parents(node):
stack = [node]
parents = []
while len(stack) > 0:
n = stack.pop()
parents.append(n)
if n.parent:
stack.append(n.parent)
return parents
p_parents, q_parents = dfs_parents(p), dfs_parents(q)
while (1):
if p_parents:
p = p_parents.pop()
if q_parents:
q = q_parents.pop()
if p == q:
pprev, qprev = p, q
else:
return pprevBinary Tree Right Side View
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example 1:

Input: root = [1,2,3,null,5,null,4]
Output: [1,3,4]Example 2:
Input: root = [1,null,3]
Output: [1,3]Example 3:
Input: root = []
Output: []Solution:
def rightSideView(root: TreeNode) -> List[int]:
if root is None:
return []
rightSide = []
def treeTraversal(node, level):
if level == len(rightSide):
rightSide.append(node.val)
for child in [node.right, node.left]:
if child:
treeTraversal(child, level+1)
treeTraversal(root, 0)
return rightSideContinuous Subarray Sum
Given an integer array nums and an integer k, return true if nums has a continuous subarray of size at least two whose elements sum up to a multiple of k, or false otherwise.
An integer x is a multiple of k if there exists an integer n such that x = n * k. 0 is always a multiple of k.
Example 1:
Input: nums = [23,2,4,6,7], k = 6
Output: true
Explanation: [2, 4] is a continuous subarray of size 2 whose elements sum up to 6.Example 2:
Input: nums = [23,2,6,4,7], k = 6
Output: true
Explanation: [23, 2, 6, 4, 7] is an continuous subarray of size 5 whose elements sum up to 42.
42 is a multiple of 6 because 42 = 7 * 6 and 7 is an integer.Example 3:
Input: nums = [23,2,6,4,7], k = 13
Output: falseSolution:
This problem is very much similar to another problem in this blog, that count the number of subarrays that adds to K. The one difference is that the difference between two numbers should be at least 1.
def checkSubarraySum( nums: List[int], k: int) -> bool:
cumsum = 0
seen = {0: -1}for i, itm in enumerate(nums):
cumsum += itm
mod = cumsum % kif mod in seen:
if i - seen[mod] > 1:
return True
else:
seen[mod] = i
return False
Kth Largest Element in an Array
Given an integer array nums and an integer k, return the kth largest element in the array.
Note that it is the kth largest element in the sorted order, not the kth distinct element.
Example 1:
Input: nums = [3,2,1,5,6,4], k = 2
Output: 5Example 2:
Input: nums = [3,2,3,1,2,4,5,5,6], k = 4
Output: 4Solution 1:
def findKthLargest(nums: List[int], k: int) -> int:
return sorted(nums)[-k]Time Complexity: O(N log N)
Space Complexity: O(1)
Solution 2:
def findKthLargest(nums: List[int], k: int) -> int:
'''
Runtime: 56 ms, faster than 96.16% of Python3 online submissions for Kth Largest Element in an Array.
Memory Usage: 15 MB, less than 73.74% of Python3 online submissions for Kth Largest Element in an Array.
'''
nums.sort(reverse=True)
return nums[k-1]Solution 3:
def findKthLargest(self, nums, k):
'''
Runtime: 52 ms, faster than 99.13% of Python3 online submissions for Kth Largest Element in an Array.
Memory Usage: 15.1 MB, less than 73.74% of Python3 online submissions for Kth Largest Element in an Array.
'''
return heapq.nlargest(k, nums)[-1]Exclusive Time of Functions
On a single-threaded CPU, we execute a program containing n functions. Each function has a unique ID between 0 and n-1.
Function calls are stored in a call stack: when a function call starts, its ID is pushed onto the stack, and when a function call ends, its ID is popped off the stack. The function whose ID is at the top of the stack is the current function being executed. Each time a function starts or ends, we write a log with the ID, whether it started or ended, and the timestamp.
You are given a list logs, where logs[i] represents the ith log message formatted as a string "{function_id}:{"start" | "end"}:{timestamp}". For example, "0:start:3" means a function call with function ID 0 started at the beginning of timestamp 3, and "1:end:2" means a function call with function ID 1 ended at the end of timestamp 2. Note that a function can be called multiple times, possibly recursively.
A function’s exclusive time is the sum of execution times for all function calls in the program. For example, if a function is called twice, one call executing for 2 time units and another call executing for 1 time unit, the exclusive time is 2 + 1 = 3.
Return the exclusive time of each function in an array, where the value at the ith index represents the exclusive time for the function with ID i.
Example 1:

Input: n = 2, logs = ["0:start:0","1:start:2","1:end:5","0:end:6"]
Output: [3,4]
Explanation:
Function 0 starts at the beginning of time 0, then it executes 2 for units of time and reaches the end of time 1.
Function 1 starts at the beginning of time 2, executes for 4 units of time, and ends at the end of time 5.
Function 0 resumes execution at the beginning of time 6 and executes for 1 unit of time.
So function 0 spends 2 + 1 = 3 units of total time executing, and function 1 spends 4 units of total time executing.Example 2:
Input: n = 1, logs = ["0:start:0","0:start:2","0:end:5","0:start:6","0:end:6","0:end:7"]
Output: [8]
Explanation:
Function 0 starts at the beginning of time 0, executes for 2 units of time, and recursively calls itself.
Function 0 (recursive call) starts at the beginning of time 2 and executes for 4 units of time.
Function 0 (initial call) resumes execution then immediately calls itself again.
Function 0 (2nd recursive call) starts at the beginning of time 6 and executes for 1 unit of time.
Function 0 (initial call) resumes execution at the beginning of time 7 and executes for 1 unit of time.
So function 0 spends 2 + 4 + 1 + 1 = 8 units of total time executing.Example 3:
Input: n = 2, logs = ["0:start:0","0:start:2","0:end:5","1:start:6","1:end:6","0:end:7"]
Output: [7,1]
Explanation:
Function 0 starts at the beginning of time 0, executes for 2 units of time, and recursively calls itself.
Function 0 (recursive call) starts at the beginning of time 2 and executes for 4 units of time.
Function 0 (initial call) resumes execution then immediately calls function 1.
Function 1 starts at the beginning of time 6, executes 1 units of time, and ends at the end of time 6.
Function 0 resumes execution at the beginning of time 6 and executes for 2 units of time.
So function 0 spends 2 + 4 + 1 = 7 units of total time executing, and function 1 spends 1 unit of total time executing.Example 4:
Input: n = 2, logs = ["0:start:0","0:start:2","0:end:5","1:start:7","1:end:7","0:end:8"]
Output: [8,1]Example 5:
Input: n = 1, logs = ["0:start:0","0:end:0"]
Output: [1]Solution:
def exclusiveTime(n: int, logs: List[str]) -> List[int]:
result = [0] * n
stack = []
for function_id, status, timestamp in [log.split(':') for log in logs]:
function_id, timestamp = int(function_id), int(timestamp)
if status == 'start':
if len(stack) > 0:
prev_fn_id, prev_ts = stack[-1]
result[prev_fn_id] += timestamp - prev_ts
stack.append([function_id, timestamp])
elif status == "end":
fn_id, value = stack.pop()
result[fn_id] += timestamp - value + 1
if len(stack):
stack[-1][1] = timestamp + 1
return resultExpression Add Operators
Given a string num that contains only digits and an integer target, return all possibilities to add the binary operators '+', '-', or '*' between the digits of num so that the resultant expression evaluates to the target value.
Example 1:
Input: num = "123", target = 6
Output: ["1*2*3","1+2+3"]Example 2:
Input: num = "232", target = 8
Output: ["2*3+2","2+3*2"]Example 3:
Input: num = "105", target = 5
Output: ["1*0+5","10-5"]Example 4:
Input: num = "00", target = 0
Output: ["0*0","0+0","0-0"]Example 5:
Input: num = "3456237490", target = 9191
Output: []Solution:
def addOperators(num: str, target: int) -> List[str]:
N, answers = len(num), []
def isValid(expr: str) -> bool:
if len(expr) > 0:
if eval(expr) == target:
if expr not in answers:
return True
return False
def recurse(pos, expr):
if pos == N and isValid(expr):
answers.append(expr)
return
for i in range(pos+1, N+1):
tmp = num[pos:i]
if tmp[0] == '0' and len(tmp) > 1:
break
if pos == 0:
recurse(i, tmp)
else:
recurse(i, expr+"*"+tmp)
recurse(i, expr+"+"+tmp)
recurse(i, expr+"-"+tmp)
recurse(0, "")
return answersInterval List Interactions
You are given two lists of closed intervals, firstList and secondList, where firstList[i] = [starti, endi] and secondList[j] = [startj, endj]. Each list of intervals is pairwise disjoint and in sorted order.
Return the intersection of these two interval lists.
A closed interval [a, b] (with a <= b) denotes the set of real numbers x with a <= x <= b.
The intersection of two closed intervals is a set of real numbers that are either empty or represented as a closed interval. For example, the intersection of [1, 3] and [2, 4] is [2, 3].
Example 1:

Input: firstList = [[0,2],[5,10],[13,23],[24,25]], secondList = [[1,5],[8,12],[15,24],[25,26]]
Output: [[1,2],[5,5],[8,10],[15,23],[24,24],[25,25]]Example 2:
Input: firstList = [[1,3],[5,9]], secondList = []
Output: []Example 3:
Input: firstList = [], secondList = [[4,8],[10,12]]
Output: []Example 4:
Input: firstList = [[1,7]], secondList = [[3,10]]
Output: [[3,7]]Solution:
def intervalIntersection(A: List[List[int]],
B: List[List[int]]) -> List[List[int]]:
ans = []
i = j = 0
while i < len(A) and j < len(B):
lo = max(A[i][0], B[j][0])
hi = min(A[i][1], B[j][1])
if lo <= hi:
ans.append([lo, hi])
if A[i][1] < B[j][1]:
i += 1
else:
j += 1
return ansReaching Points
Given four integers sx, sy, tx, and ty, return true if it is possible to convert the point (sx, sy) to the point (tx, ty) through some operations, or false otherwise.
The allowed operation on some point (x, y) is to convert it to either (x, x + y) or (x + y, y).
Example 1:
Input: sx = 1, sy = 1, tx = 3, ty = 5
Output: true
Explanation:
One series of moves that transforms the starting point to the target is:
(1, 1) -> (1, 2)
(1, 2) -> (3, 2)
(3, 2) -> (3, 5)Example 2:
Input: sx = 1, sy = 1, tx = 2, ty = 2
Output: falseExample 3:
Input: sx = 1, sy = 1, tx = 1, ty = 1
Output: trueSolution:

The typical path to reach from Sx, Sy is shown in the table above.
From the table we could see a pattern.
def reachingPoints(sx: int,
sy: int,
tx: int,
ty: int) -> bool:
while tx >= sx and ty >= sy:
if tx > ty and (tx-sx)//ty:
tx -= ty*((tx-sx)//ty)
elif ty > tx and (ty-sy)//tx:
ty -= tx*((ty-sy)//tx)
else:
break
return ((tx==sx) and (ty==sy))