Member-only story
Cracking the Code of Retrieval Systems: Challenges for Scalable Intelligence
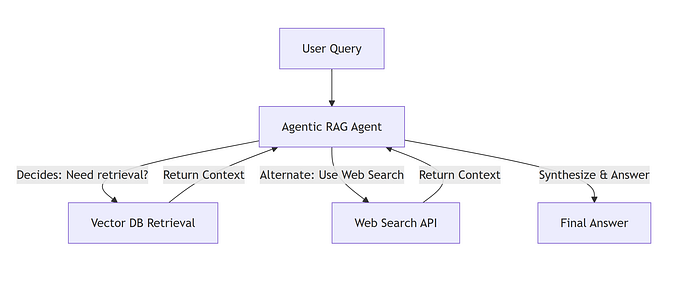
Every interaction with a search engine, recommendation platform, or AI assistant begins with a retrieval system. These systems shape how we find and interact with information. But building a robust retrieval system is no small feat — it involves tackling technical and engineering challenges like scalability, accuracy, and user adaptation. Inspired by a recent interview, this article delves into these challenges and explores design patterns that make retrieval systems smarter, faster, and more reliable.

Challenges
The challenges in retrieval system design can be broadly classified into technical and engineering challenges.
Technical Challenges
Relevance
The cornerstone of any retrieval system is its ability to identify relevant documents. While metrics like cosine similarity are widely used, they aren’t always sufficient. Metrics are sensitive to vector lengths and embedding space properties, and their effectiveness varies by use case. For instance, multi-stage retrieval combines initial filtering with ranking/re-ranking algorithms to refine results. Choosing the right metric requires careful consideration of the embedding model, data characteristics, and intended outcomes.